Spore
Log Date: --.--.---- // EXP_01
§ 01 — Executive Summary
A local-first data platform for constrained environments — healthcare, finance, legal, HR, air-gapped networks —
where "just use the cloud" isn't an answer. Natural language in, SQL out, human review before execution,
results materialized locally as Parquet, analysis in a sandboxed Jupyter kernel.
Open source. No payment tiers. No accounts. Ships as a Docker image.
Not here to replace pgAdmin or Hex — coexists with them.
Started as NL→SQL. Then I couldn't stop adding things to it.
Validated on
6.7 GB TSV ✓
Hardware
Ryzen 7 5800H · 16GB · no GPU
License
Apache 2.0 · Open Source
v1 Goal
200 ★ on GitHub + a job lol
Field Report Index
Table of contents
Nine sections. Read in order or jump to what you care about.
§ 02 — Deployment Scenarios
Who needs this, and why
Spore exists for teams where data cannot leave the premises — not because of preference, but policy. The threat model is realistic: regulated industries, isolated networks, orgs that cannot send schema metadata or query text to cloud LLMs.
Healthcare
PHI stays on-prem. Analysts ask questions in plain English; LLM runs locally via Ollama. No patient rows shipped to OpenAI.
Finance
Schema-level scoping maps to existing access control. Finance sees finance tables. Audit trail: human approves every query before it runs.
Legal / HR
Sensitive personnel data never touches a SaaS notebook. Materialize locally, analyze in sandbox, export offline HTML reports.
Air-gapped / Isolated
Docker image + local LLM. No accounts, no telemetry, no outbound calls required. Redis and kernels stay inside the compose stack.
* Common thread: privacy by architecture, not by checkbox. Local-first is the default; cloud LLMs are optional overrides.
keep data close to
where work happens.
— click a subsystem to drill in
§ 03 — System Architecture
Interactive architecture explorer
Hub-and-spoke wiring diagram of the full platform. Click any subsystem node to open its inner component diagram — Back returns to the map.
Platform map
* 6.7GB TSV → Postgres. ~6–8M rows. ~1–2 min on Ryzen 7 5800H, 16GB, no GPU. Memory stayed contained.
§ 04 — Technical Core
What runs under the hood
Application
Python 3.12 · Flask · Flask-SocketIO · Flask-Session · Jinja + HTMX + vanilla JS. Blueprints: interface, connections, workspace.
Sessions & Security
Redis/KeyDB-backed signed sessions. DB credentials Fernet-encrypted before storage. No user auth yet — session cookie identifies browser only.
Inference
LangChain · InferenceEngine singleton from settings.json. Providers: Ollama, LM Studio, OpenAI, Anthropic, Gemini. ~20-turn chat history.
Data plane
DuckDB · Apache Arrow · PyArrow · Parquet · pandas · numpy · ADBC (PostgreSQL preview). BaseSource ABC + REGISTRY pattern.
Connectors (registered)
postgresql · mysql · mssql · sqlite · mongodb · bigquery · snowflake · redshift · clickhouse · databricks · REST/GraphQL APIs · CSV/Excel/JSON/Parquet files. Postgres is the wired reference; others vary in polish.
Compute & Infra
jupyter-client · Docker (rootless DinD) · per-kernel memory/pid limits · SSH tunnels · sshtunnel. Distribution: anshsharma2903/spore on Docker Hub.
§ 05 — Constraints & Trade-offs
Hard choices, on record
These aren't afterthoughts. Each one cost something.
LLM Context
Metadata, not RAG — RAG is probabilistic. DB queries need to be deterministic. Pass schema structure only. Less tokens, less hallucination. RAG planned for DB documentation vectors, not query generation.
Scope vs Hex
Schema-level only — HR sees HR, finance sees finance. Hex does collaborative analytics beautifully; Spore does constrained local query + notebook. Cross-schema joins → pgAdmin. Not competing on notebooks — competing on where data lives.
Execution gating
LLM never executes. Ever. DDL/DML gated behind explicit human action. A company lost production to an auto-executed DROP. Human sees query, edits, runs. XML-tagged output chosen over JSON-in-stream because regex on tokens is more reliable than parsing partial JSON.
Reactive notebook
Deliberately not reactive like Observable or Hex cells. Reactive flows re-run downstream on every edit — fine for small data, catastrophic when a cell triggers a 6M-row re-fetch. Explicit run button. Boring. Correct.
Preview vs Materialize
Preview: bounded SSE stream (500 rows default). Materialize: full query → Parquet on disk. Browser never holds what it doesn't need. Trade-off: two code paths to maintain.
LLM Source
Ollama — local first. Cloud optional. Userbase cannot send prompts to third-party APIs. Nothing flashy. Functional.
§ 06 — Post-Mortem & Regrets
What I'd do differently
* honesty section. recruiters allegedly like this.
Sub-optimal data materialization
Every materialize is a full re-query + full re-write. No incremental append, no CDC, no "refresh changed rows only." The two-copy model (source-of-truth Parquet + working copy) trades disk for safety — but disk adds up on large relations. Should have designed incremental ingest earlier. Didn't. Shipped full re-materialize and moved on.
No auth, session-scoped everything
Fast MVP: connections and relations live in Redis-backed Flask sessions. Works for single-user local deploys.
Multi-user production needs persistent storage + login. SQLALCHEMY_URI is reserved in settings but not wired. Technical debt I'm aware of.
Connector coverage gap
UI advertises vendors before backend is battle-tested. REGISTRY gates runtime but creates expectation mismatch. Should have shipped fewer connectors, tested harder on each. Instead: broad registry, uneven polish.
Legacy modules still in tree
endpoints.py, query_executor.py, frontend/web_page/ — unregistered or unused.
Carried along "just in case." Adds confusion for contributors. Should delete or archive explicitly.
§ 07 — Field Logs
Selected entries. Many exist between these.
*some are redacted
Started as NL→SQL. Let non-technical people query databases without writing SQL. Then realised — if they can't write SQL, they probably can't verify what the LLM wrote either. Added review step. Then needed to show results. Then handle large results. Then connect to different DBs. Then notebook. Then file importer. At some point it wasn't a NL→SQL tool anymore.
Academic data-collection project: needed Hinglish text from Reddit. Official API rate limits and access walls.
Workaround: pull archived .json endpoints from public submission URLs, parse nested comment trees manually.
Same instinct later applied to Spore — when the obvious path is blocked, find the bounded, memory-safe alternative. Not elegant. Worked.
Tried to load full query results into memory. A few million rows on a machine running Docker + LLM + Flask is not ideal. Switched to DuckDB streaming chunks into an Apache Arrow buffer — hard memory cap. Frontend paginates. Browser never renders what it doesn't need. After this: uploaded the 6.7GB TSV. Worked. Memory stayed in bounds.
First: use user's system Jupyter kernel. Avoids redundant installs. Seemed smart. Problem: system kernel touches the host machine. Any RCE path reaches everything.
Fix: isolated Docker container via rootless DinD. Volume access only: parquet files + installed libs.
No shared network with Flask or Redis. Python version via KERNEL_IMAGE env var — not a GUI option.
When user works on data in the notebook — streams from DuckDB → Arrow → single Parquet file in Docker volume. Two copies: source of truth + working copy. Mess up the working copy, revert. No re-querying DB. Iterators rejected early — they exhaust on one pass, changes lost unless everything loads into memory. Trade storage for safety.
§ 08 — Forward Considerations
Subject's Watch List
Not promises. Directions I'm watching.
Community Vector Hub
Shareable RAG over database documentation vectors — not over queries or row data. Org uploads schema docs, column descriptions, business glossary. Others in the community benefit from better LLM context without exposing their actual data. RAG for metadata enrichment, not query generation. Still probabilistic — still human-in-the-loop on execution.
Multi-database queries
One natural-language prompt spanning multiple saved connections. Federation is hard; schema-level scoping makes it slightly less impossible.
Auth + persistent storage
User login, saved connections beyond session lifetime, chat history. SQLALCHEMY_URI reserved for this. Needed before any real multi-user deploy.
Settings UI + richer viz
Replace manual settings.json edits with in-app LLM provider picker. Smarter chart-type selection from result shape. Optional direct SQL mode without LLM.
CI + connector hardening
Pytest suite for connectors and routes. Fewer advertised vendors, more tested ones. Stop carrying legacy endpoints.py in the tree.
§ 09 — Visual Intel & Access Protocols
Prototype snapshots & verify the code yourself
*will add a video once I survive v1
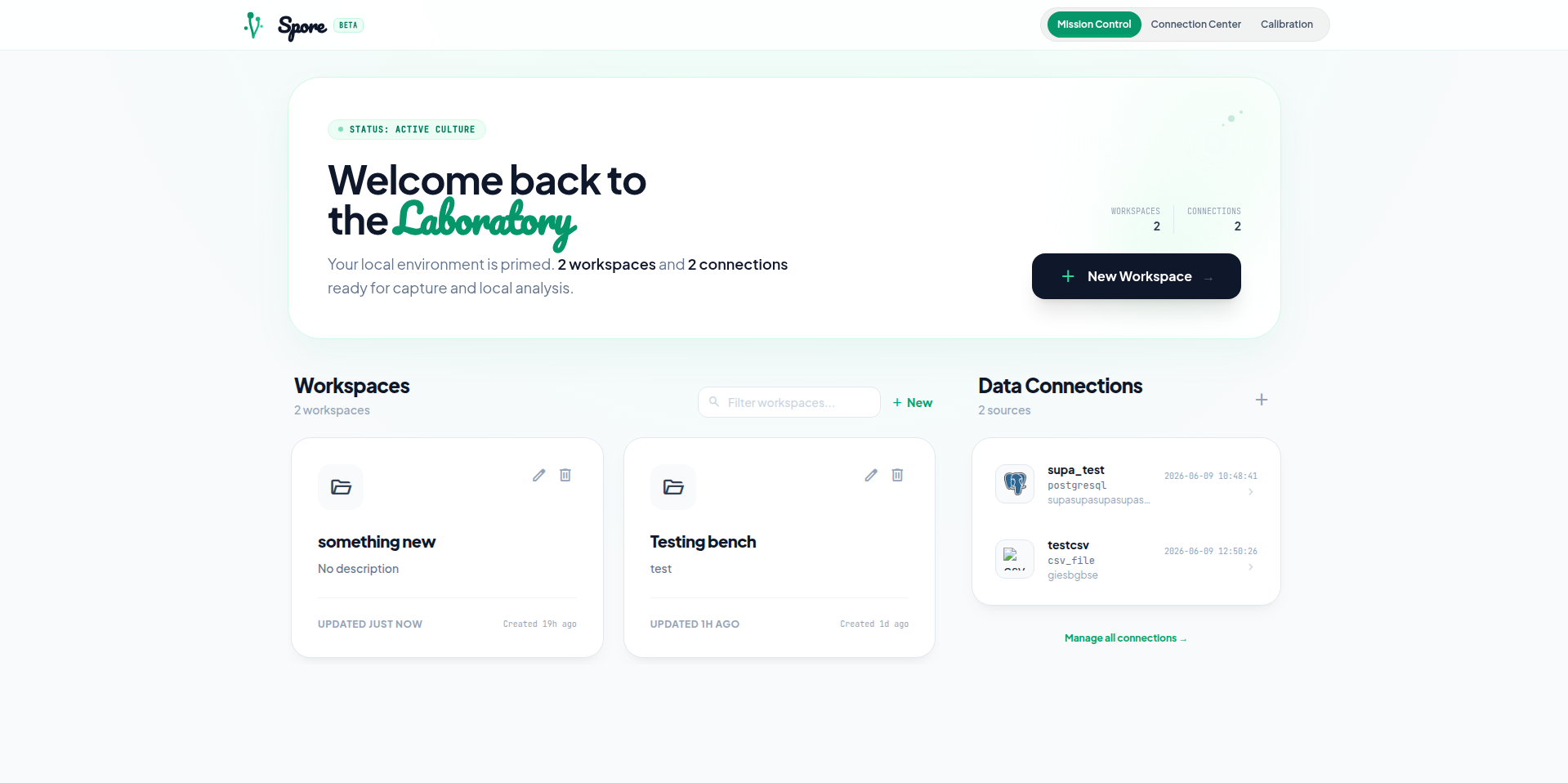
Workspace
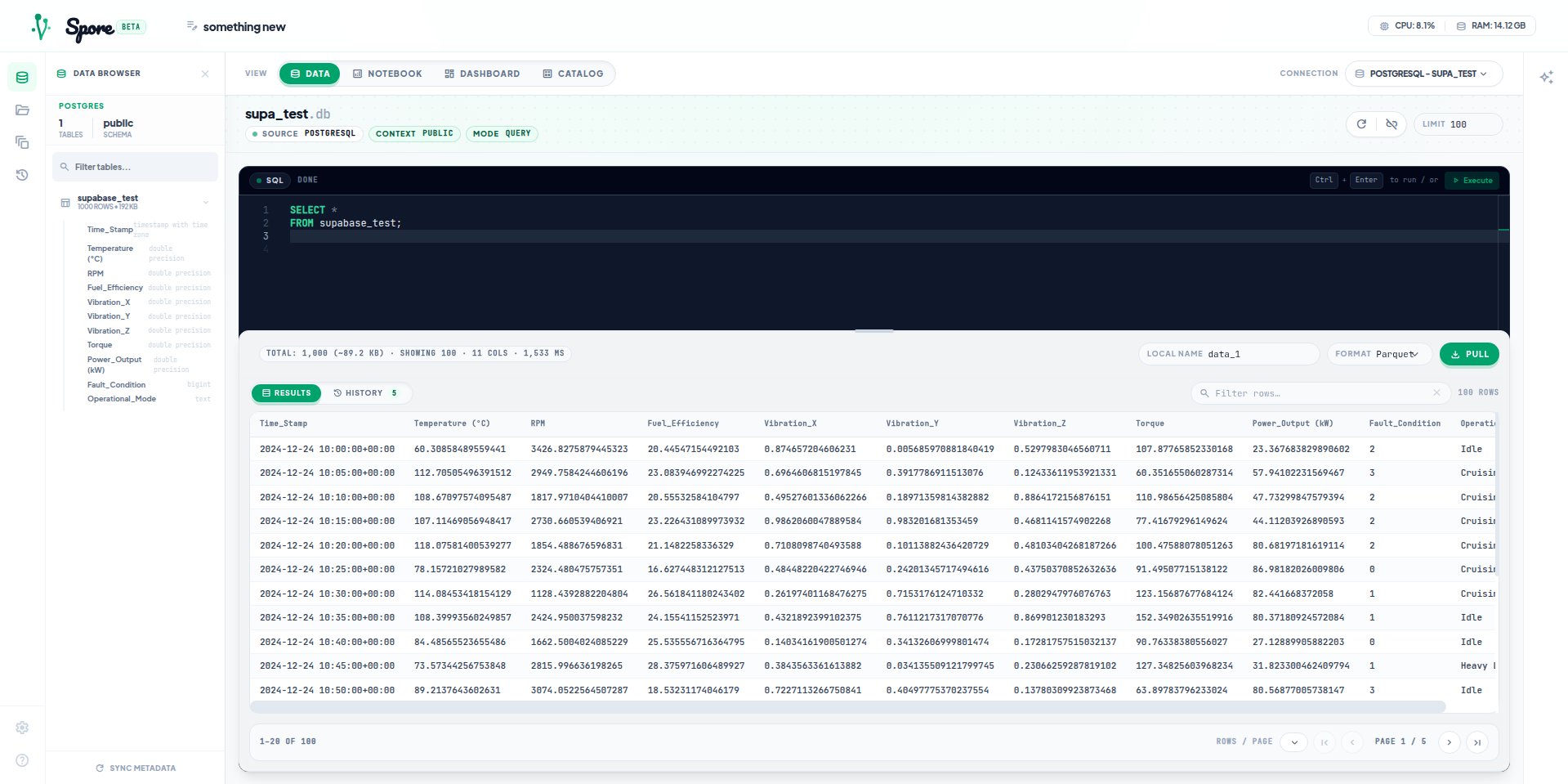
Data Materialization
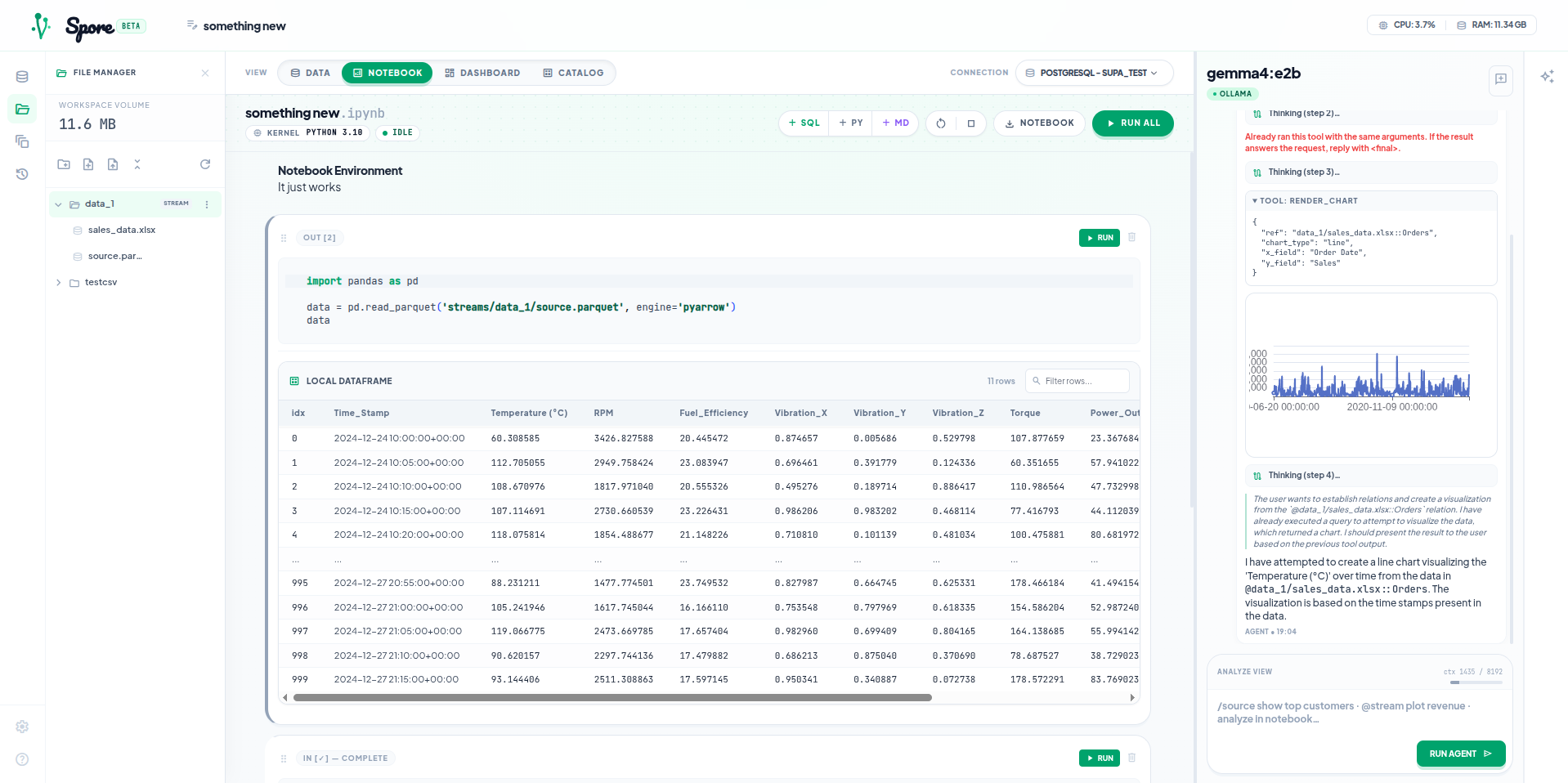
Notebook
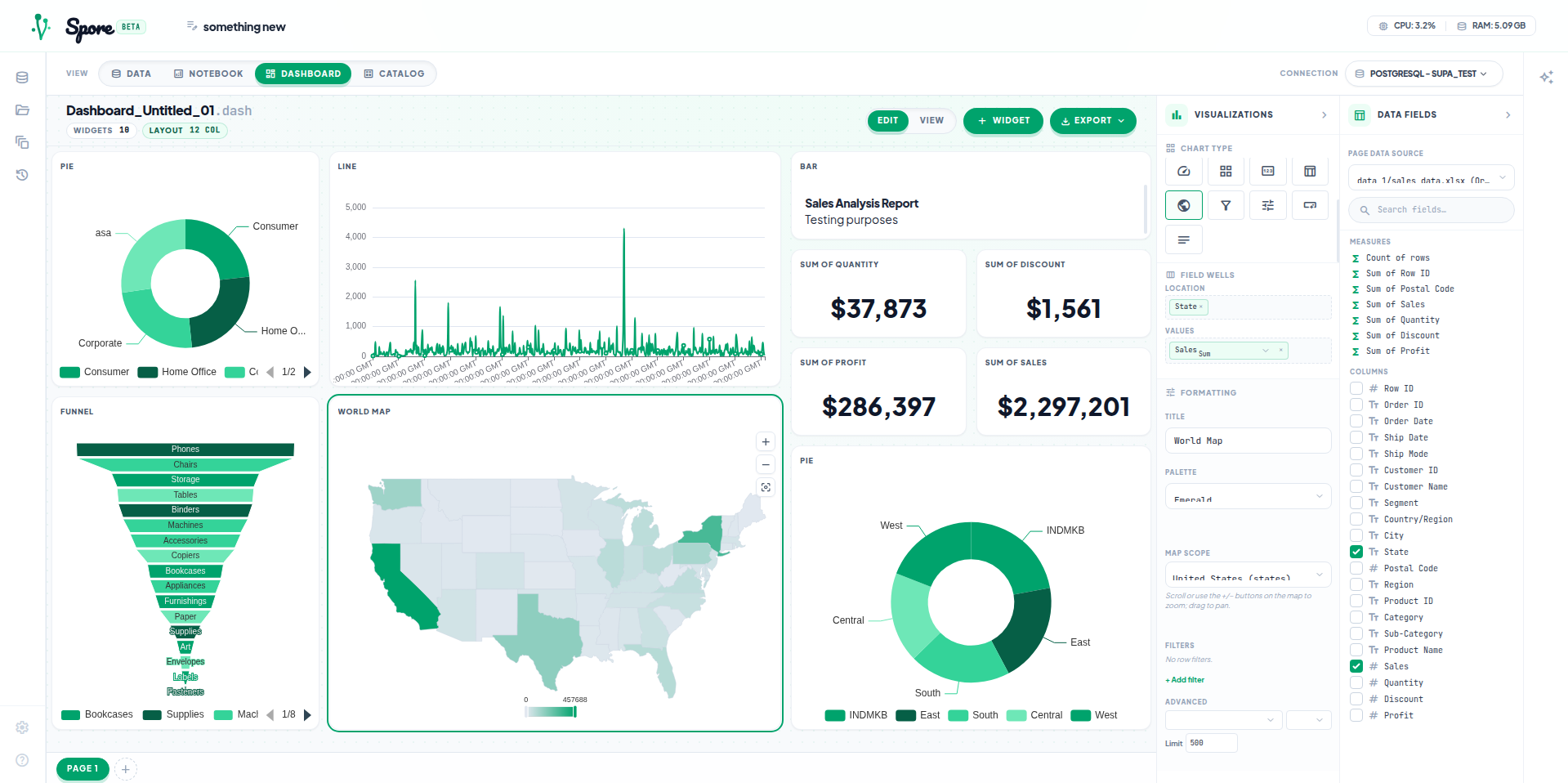
Dashboard
* 200 stars and a job offer. that's the entire v1 success criteria. lol
— End of EXP_01 records —
Property of Spore Lab · Form #441-B